Deduplication¶
Introduction¶
Applying data deduplication on an existing software stack is not easy due to additional metadata management and original data processing procedure.
In a typical deduplication system, the input source as a data object is split into multiple chunks by a chunking algorithm. The deduplication system then compares each chunk with the existing data chunks, stored in the storage previously. To this end, a fingerprint index that stores the hash value of each chunk is employed by the deduplication system in order to easily find the existing chunks by comparing hash value rather than searching all contents that reside in the underlying storage.
There are many challenges in order to implement deduplication on top of Ceph. Among them, two issues are essential for deduplication. First is managing scalability of fingerprint index; Second is it is complex to ensure compatibility between newly applied deduplication metadata and existing metadata.
Key Idea¶
1. Content hashing (Double hashing): Each client can find an object data for an object ID using CRUSH. With CRUSH, a client knows object’s location in Base tier. By hashing object’s content at Base tier, a new OID (chunk ID) is generated. Chunk tier stores in the new OID that has a partial content of original object.
Client 1 -> OID=1 -> HASH(1’s content)=K -> OID=K -> CRUSH(K) -> chunk’s location
2. Self-contained object: The external metadata design makes difficult for integration with storage feature support since existing storage features cannot recognize the additional external data structures. If we can design data deduplication system without any external component, the original storage features can be reused.
More details in https://ieeexplore.ieee.org/document/8416369
Design¶
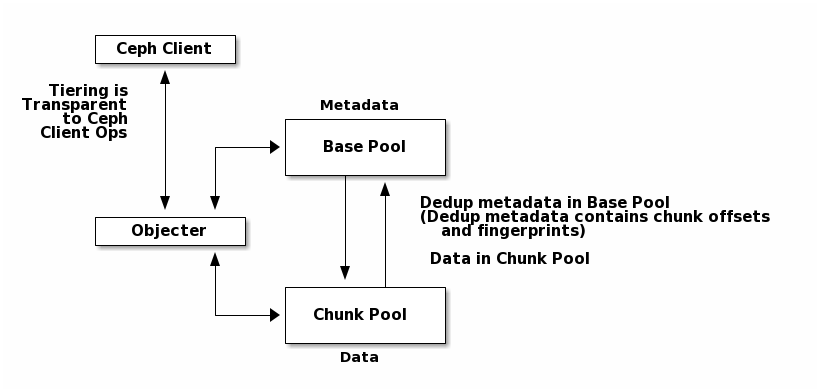
Pool-based object management: We define two pools. The metadata pool stores metadata objects and the chunk pool stores chunk objects. Since these two pools are divided based on the purpose and usage, each pool can be managed more efficiently according to its different characteristics. Base pool and the chunk pool can separately select a redundancy scheme between replication and erasure coding depending on its usage and each pool can be placed in a different storage location depending on the required performance.
Manifest Object: Metadata objects are stored in the base pool, which contains metadata for data deduplication.
struct object_manifest_t {
enum {
TYPE_NONE = 0,
TYPE_REDIRECT = 1,
TYPE_CHUNKED = 2,
};
uint8_t type; // redirect, chunked, ...
hobject_t redirect_target;
std::map<uint64_t, chunk_info_t> chunk_map;
}
A chunk Object: Chunk objects are stored in the chunk pool. Chunk object contains chunk data and its reference count information.
Although chunk objects and manifest objects have a different purpose from existing objects, they can be handled the same way as original objects. Therefore, to support existing features such as replication, no additional operations for dedup are needed.
Usage¶
To set up deduplication pools, you must have two pools. One will act as the base pool and the other will act as the chunk pool. The base pool need to be configured with fingerprint_algorithm option as follows.
ceph osd pool set $BASE_POOL fingerprint_algorithm sha1|sha256|sha512
--yes-i-really-mean-it
Create objects
- rados -p base_pool put foo ./foo - rados -p chunk_pool put foo-chunk ./foo-chunk
Make a manifest object
- rados -p base_pool set-chunk foo $START_OFFSET $END_OFFSET --target-pool chunk_pool foo-chunk $START_OFFSET --with-reference
Interface¶
set-redirect
set redirection between a base_object in the base_pool and a target_object in the target_pool. A redirected object will forward all operations from the client to the target_object.
rados -p base_pool set-redirect <base_object> --target-pool <target_pool> <target_object>
set-chunk
set chunk-offset in a source_object to make a link between it and a target_object.
rados -p base_pool set-chunk <source_object> <offset> <length> --target-pool <caspool> <target_object> <taget-offset>
tier-promote
promote the object (including chunks).
rados -p base_pool tier-promote <obj-name>
unset-manifest
unset manifest option from the object that has manifest.
rados -p base_pool unset-manifest <obj-name>
tier-flush
flush the object that has chunks to the chunk pool.
rados -p base_pool tier-flush <obj-name>
Dedup tool¶
Dedup tool has two features: finding optimal chunk offset for dedup chunking and fixing the reference count.
find optimal chunk offset
fixed chunk
To find out a fixed chunk length, you need to run following command many times while changing the chunk_size.
ceph-dedup-tool --op estimate --pool $POOL --chunk-size chunk_size --chunk-algorithm fixed --fingerprint-algorithm sha1|sha256|sha512
rabin chunk(Rabin-karp algorithm)
As you know, Rabin-karp algorithm is string-searching algorithm based on a rolling-hash. But rolling-hash is not enough to do deduplication because we don’t know the chunk boundary. So, we need content-based slicing using a rolling hash for content-defined chunking. The current implementation uses the simplest approach: look for chunk boundaries by inspecting the rolling hash for pattern(like the lower N bits are all zeroes).
Usage
Users who want to use deduplication need to find an ideal chunk offset. To find out ideal chunk offset, Users should discover the optimal configuration for their data workload via ceph-dedup-tool. And then, this chunking information will be used for object chunking through set-chunk api.
ceph-dedup-tool --op estimate --pool $POOL --min-chunk min_size --chunk-algorithm rabin --fingerprint-algorithm rabin
ceph-dedup-tool has many options to utilize rabin chunk. These are options for rabin chunk.
--mod-prime <uint64_t> --rabin-prime <uint64_t> --pow <uint64_t> --chunk-mask-bit <uint32_t> --window-size <uint32_t> --min-chunk <uint32_t> --max-chunk <uint64_t>
Users need to refer following equation to use above options for rabin chunk.
rabin_hash = (rabin_hash * rabin_prime + new_byte - old_byte * pow) % (mod_prime)
Fixed chunk vs content-defined chunk
Content-defined chunking may or not be optimal solution. For example,
Data chunk A : abcdefgabcdefgabcdefg
Let’s think about Data chunk A’s deduplication. Ideal chunk offset is from 1 to 7 (abcdefg). So, if we use fixed chunk, 7 is optimal chunk length. But, in the case of content-based slicing, the optimal chunk length could not be found (dedup ratio will not be 100%). Because we need to find optimal parameter such as boundary bit, window size and prime value. This is as easy as fixed chunk. But, content defined chunking is very effective in the following case.
Data chunk B : abcdefgabcdefgabcdefg
Data chunk C : Tabcdefgabcdefgabcdefg
fix reference count
The key idea behind of reference counting for dedup is false-positive, which means (manifest object (no ref), chunk object(has ref)) happen instead of (manifest object (has ref), chunk 1(no ref)). To fix such inconsistency, ceph-dedup-tool supports chunk_scrub.
ceph-dedup-tool --op chunk_scrub --chunk_pool $CHUNK_POOL