Erasure code¶
By default, Ceph pools are created with the type “replicated”. In replicated-type pools, every object is copied to multiple disks. This multiple copying is the method of data protection known as “replication”.
By contrast, erasure-coded pools use a method of data protection that is different from replication. In erasure coding, data is broken into fragments of two kinds: data blocks and parity blocks. If a drive fails or becomes corrupted, the parity blocks are used to rebuild the data. At scale, erasure coding saves space relative to replication.
In this documentation, data blocks are referred to as “data chunks” and parity blocks are referred to as “coding chunks”.
Erasure codes are also called “forward error correction codes”. The first forward error correction code was developed in 1950 by Richard Hamming at Bell Laboratories.
Creating a sample erasure-coded pool¶
The simplest erasure-coded pool is similar to RAID5 and requires at least three hosts:
ceph osd pool create ecpool erasure
pool 'ecpool' created
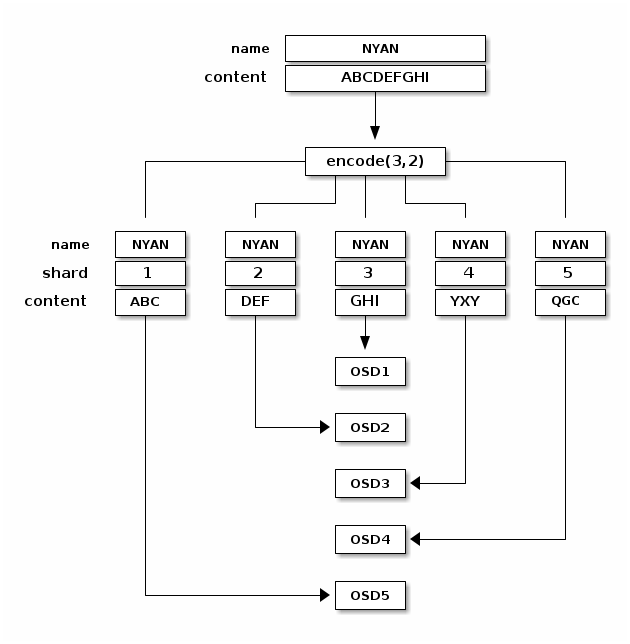
echo ABCDEFGHI | rados --pool ecpool put NYAN -
rados --pool ecpool get NYAN -
ABCDEFGHI
Erasure-code profiles¶
The default erasure-code profile can sustain the overlapping loss of two OSDs without losing data. This erasure-code profile is equivalent to a replicated pool of size three, but with different storage requirements: instead of requiring 3TB to store 1TB, it requires only 2TB to store 1TB. The default profile can be displayed with this command:
ceph osd erasure-code-profile get default
k=2
m=2
plugin=jerasure
crush-failure-domain=host
technique=reed_sol_van
Note
The profile just displayed is for the default erasure-coded pool, not the simplest erasure-coded pool. These two pools are not the same:
The default erasure-coded pool has two data chunks (K) and two coding chunks (M). The profile of the default erasure-coded pool is “k=2 m=2”.
The simplest erasure-coded pool has two data chunks (K) and one coding chunk (M). The profile of the simplest erasure-coded pool is “k=2 m=1”.
Choosing the right profile is important because the profile cannot be modified after the pool is created. If you find that you need an erasure-coded pool with a profile different than the one you have created, you must create a new pool with a different (and presumably more carefully considered) profile. When the new pool is created, all objects from the wrongly configured pool must be moved to the newly created pool. There is no way to alter the profile of a pool after the pool has been created.
The most important parameters of the profile are K, M, and crush-failure-domain because they define the storage overhead and the data durability. For example, if the desired architecture must sustain the loss of two racks with a storage overhead of 67%, the following profile can be defined:
ceph osd erasure-code-profile set myprofile \
k=3 \
m=2 \
crush-failure-domain=rack
ceph osd pool create ecpool erasure myprofile
echo ABCDEFGHI | rados --pool ecpool put NYAN -
rados --pool ecpool get NYAN -
ABCDEFGHI
The NYAN object will be divided in three (K=3) and two additional chunks will be created (M=2). The value of M defines how many OSDs can be lost simultaneously without losing any data. The crush-failure-domain=rack will create a CRUSH rule that ensures no two chunks are stored in the same rack.
More information can be found in the erasure-code profiles documentation.
Erasure Coding with Overwrites¶
By default, erasure-coded pools work only with operations that perform full object writes and appends (for example, RGW).
Since Luminous, partial writes for an erasure-coded pool may be enabled with a per-pool setting. This lets RBD and CephFS store their data in an erasure-coded pool:
ceph osd pool set ec_pool allow_ec_overwrites true
This can be enabled only on a pool residing on BlueStore OSDs, since BlueStore’s checksumming is used during deep scrubs to detect bitrot or other corruption. Using Filestore with EC overwrites is not only unsafe, but it also results in lower performance compared to BlueStore.
Erasure-coded pools do not support omap, so to use them with RBD and
CephFS you must instruct them to store their data in an EC pool and
their metadata in a replicated pool. For RBD, this means using the
erasure-coded pool as the --data-pool during image creation:
rbd create --size 1G --data-pool ec_pool replicated_pool/image_name
For CephFS, an erasure-coded pool can be set as the default data pool during file system creation or via file layouts.
Erasure-coded pools and cache tiering¶
Erasure-coded pools require more resources than replicated pools and lack some of the functionality supported by replicated pools (for example, omap). To overcome these limitations, one can set up a cache tier before setting up the erasure-coded pool.
For example, if the pool hot-storage is made of fast storage, the following commands will place the hot-storage pool as a tier of ecpool in writeback mode:
ceph osd tier add ecpool hot-storage
ceph osd tier cache-mode hot-storage writeback
ceph osd tier set-overlay ecpool hot-storage
The result is that every write and read to the ecpool actually uses the hot-storage pool and benefits from its flexibility and speed.
More information can be found in the cache tiering documentation. Note, however, that cache tiering is deprecated and may be removed completely in a future release.
Erasure-coded pool recovery¶
If an erasure-coded pool loses any data shards, it must recover them from others. This recovery involves reading from the remaining shards, reconstructing the data, and writing new shards.
In Octopus and later releases, erasure-coded pools can recover as long as there are at least K shards available. (With fewer than K shards, you have actually lost data!)
Prior to Octopus, erasure-coded pools required that at least min_size shards be
available, even if min_size was greater than K. This was a conservative
decision made out of an abundance of caution when designing the new pool
mode. As a result, however, pools with lost OSDs but without complete data loss were
unable to recover and go active without manual intervention to temporarily change
the min_size setting.
We recommend that min_size be K+2 or greater to prevent loss of writes and
loss of data.
Glossary¶
- chunk
When the encoding function is called, it returns chunks of the same size as each other. There are two kinds of chunks: (1) data chunks, which can be concatenated to reconstruct the original object, and (2) coding chunks, which can be used to rebuild a lost chunk.
- K
The number of data chunks into which an object is divided. For example, if K = 2, then a 10KB object is divided into two objects of 5KB each.
- M
The number of coding chunks computed by the encoding function. M is equal to the number of OSDs that can be missing from the cluster without the cluster suffering data loss. For example, if there are two coding chunks, then two OSDs can be missing without data loss.