Placement Groups¶
Autoscaling placement groups¶
Placement groups (PGs) are an internal implementation detail of how Ceph distributes data. You can allow the cluster to either make recommendations or automatically tune PGs based on how the cluster is used by enabling pg-autoscaling.
Each pool in the system has a pg_autoscale_mode property that can be set to off, on, or warn.
off: Disable autoscaling for this pool. It is up to the administrator to choose an appropriate PG number for each pool. Please refer to Choosing the number of Placement Groups for more information.on: Enable automated adjustments of the PG count for the given pool.warn: Raise health alerts when the PG count should be adjusted
To set the autoscaling mode for an existing pool:
ceph osd pool set <pool-name> pg_autoscale_mode <mode>
For example to enable autoscaling on pool foo:
ceph osd pool set foo pg_autoscale_mode on
You can also configure the default pg_autoscale_mode that is
set on any pools that are subsequently created:
ceph config set global osd_pool_default_pg_autoscale_mode <mode>
You can disable or enable the autoscaler for all pools with
the noautoscale flag. By default this flag is set to be off,
but you can turn it on by using the command:
ceph osd pool set noautoscale
You can turn it off using the command:
ceph osd pool unset noautoscale
To get the value of the flag use the command:
ceph osd pool get noautoscale
Viewing PG scaling recommendations¶
You can view each pool, its relative utilization, and any suggested changes to the PG count with this command:
ceph osd pool autoscale-status
Output will be something like:
POOL SIZE TARGET SIZE RATE RAW CAPACITY RATIO TARGET RATIO EFFECTIVE RATIO BIAS PG_NUM NEW PG_NUM AUTOSCALE BULK
a 12900M 3.0 82431M 0.4695 8 128 warn True
c 0 3.0 82431M 0.0000 0.2000 0.9884 1.0 1 64 warn True
b 0 953.6M 3.0 82431M 0.0347 8 warn False
SIZE is the amount of data stored in the pool. TARGET SIZE, if present, is the amount of data the administrator has specified that they expect to eventually be stored in this pool. The system uses the larger of the two values for its calculation.
RATE is the multiplier for the pool that determines how much raw storage capacity is consumed. For example, a 3 replica pool will have a ratio of 3.0, while a k=4,m=2 erasure coded pool will have a ratio of 1.5.
RAW CAPACITY is the total amount of raw storage capacity on the OSDs that are responsible for storing this pool’s (and perhaps other pools’) data. RATIO is the ratio of that total capacity that this pool is consuming (i.e., ratio = size * rate / raw capacity).
TARGET RATIO, if present, is the ratio of storage that the administrator has specified that they expect this pool to consume relative to other pools with target ratios set. If both target size bytes and ratio are specified, the ratio takes precedence.
EFFECTIVE RATIO is the target ratio after adjusting in two ways:
subtracting any capacity expected to be used by pools with target size set
normalizing the target ratios among pools with target ratio set so they collectively target the rest of the space. For example, 4 pools with target_ratio 1.0 would have an effective ratio of 0.25.
The system uses the larger of the actual ratio and the effective ratio for its calculation.
BIAS is used as a multiplier to manually adjust a pool’s PG based on prior information about how much PGs a specific pool is expected to have.
PG_NUM is the current number of PGs for the pool (or the current
number of PGs that the pool is working towards, if a pg_num
change is in progress). NEW PG_NUM, if present, is what the
system believes the pool’s pg_num should be changed to. It is
always a power of 2, and will only be present if the “ideal” value
varies from the current value by more than a factor of 3 by default.
This factor can be be adjusted with:
ceph osd pool set threshold 2.0
AUTOSCALE, is the pool pg_autoscale_mode
and will be either on, off, or warn.
The final column, BULK determines if the pool is bulk
and will be either True or False. A bulk pool
means that the pool is expected to be large and should start out
with large amount of PGs for performance purposes. On the other hand,
pools without the bulk flag are expected to be smaller e.g.,
.mgr or meta pools.
Automated scaling¶
Allowing the cluster to automatically scale PGs based on usage is the
simplest approach. Ceph will look at the total available storage and
target number of PGs for the whole system, look at how much data is
stored in each pool, and try to apportion the PGs accordingly. The
system is relatively conservative with its approach, only making
changes to a pool when the current number of PGs (pg_num) is more
than 3 times off from what it thinks it should be.
The target number of PGs per OSD is based on the
mon_target_pg_per_osd configurable (default: 100), which can be
adjusted with:
ceph config set global mon_target_pg_per_osd 100
The autoscaler analyzes pools and adjusts on a per-subtree basis. Because each pool may map to a different CRUSH rule, and each rule may distribute data across different devices, Ceph will consider utilization of each subtree of the hierarchy independently. For example, a pool that maps to OSDs of class ssd and a pool that maps to OSDs of class hdd will each have optimal PG counts that depend on the number of those respective device types.
In the case where a pool uses OSDs under two or more CRUSH roots, e.g., (shadow trees with both ssd and hdd devices), the autoscaler will issue a warning to the user in the manager log stating the name of the pool and the set of roots that overlap each other. The autoscaler will not scale any pools with overlapping roots because this can cause problems with the scaling process. We recommend making each pool belong to only one root (one OSD class) to get rid of the warning and ensure a successful scaling process.
The autoscaler uses the bulk flag to determine which pool should start out with a full complement of PGs and only scales down when the usage ratio across the pool is not even. However, if the pool doesn’t have the bulk flag, the pool will start out with minimal PGs and only when there is more usage in the pool.
To create pool with bulk flag:
ceph osd pool create <pool-name> --bulk
To set/unset bulk flag of existing pool:
ceph osd pool set <pool-name> bulk <true/false/1/0>
To get bulk flag of existing pool:
ceph osd pool get <pool-name> bulk
Specifying expected pool size¶
When a cluster or pool is first created, it will consume a small
fraction of the total cluster capacity and will appear to the system
as if it should only need a small number of placement groups.
However, in most cases cluster administrators have a good idea which
pools are expected to consume most of the system capacity over time.
By providing this information to Ceph, a more appropriate number of
PGs can be used from the beginning, preventing subsequent changes in
pg_num and the overhead associated with moving data around when
those adjustments are made.
The target size of a pool can be specified in two ways: either in
terms of the absolute size of the pool (i.e., bytes), or as a weight
relative to other pools with a target_size_ratio set.
For example:
ceph osd pool set mypool target_size_bytes 100T
will tell the system that mypool is expected to consume 100 TiB of space. Alternatively:
ceph osd pool set mypool target_size_ratio 1.0
will tell the system that mypool is expected to consume 1.0 relative
to the other pools with target_size_ratio set. If mypool is the
only pool in the cluster, this means an expected use of 100% of the
total capacity. If there is a second pool with target_size_ratio
1.0, both pools would expect to use 50% of the cluster capacity.
You can also set the target size of a pool at creation time with the optional --target-size-bytes <bytes> or --target-size-ratio <ratio> arguments to the ceph osd pool create command.
Note that if impossible target size values are specified (for example,
a capacity larger than the total cluster) then a health warning
(POOL_TARGET_SIZE_BYTES_OVERCOMMITTED) will be raised.
If both target_size_ratio and target_size_bytes are specified
for a pool, only the ratio will be considered, and a health warning
(POOL_HAS_TARGET_SIZE_BYTES_AND_RATIO) will be issued.
Specifying bounds on a pool’s PGs¶
It is also possible to specify a minimum number of PGs for a pool. This is useful for establishing a lower bound on the amount of parallelism client will see when doing IO, even when a pool is mostly empty. Setting the lower bound prevents Ceph from reducing (or recommending you reduce) the PG number below the configured number.
You can set the minimum or maximum number of PGs for a pool with:
ceph osd pool set <pool-name> pg_num_min <num>
ceph osd pool set <pool-name> pg_num_max <num>
You can also specify the minimum or maximum PG count at pool creation
time with the optional --pg-num-min <num> or --pg-num-max
<num> arguments to the ceph osd pool create command.
A preselection of pg_num¶
When creating a new pool with:
ceph osd pool create {pool-name} [pg_num]
it is optional to choose the value of pg_num. If you do not
specify pg_num, the cluster can (by default) automatically tune it
for you based on how much data is stored in the pool (see above, Autoscaling placement groups).
Alternatively, pg_num can be explicitly provided. However,
whether you specify a pg_num value or not does not affect whether
the value is automatically tuned by the cluster after the fact. To
enable or disable auto-tuning:
ceph osd pool set {pool-name} pg_autoscale_mode (on|off|warn)
The “rule of thumb” for PGs per OSD has traditionally be 100. With the additional of the balancer (which is also enabled by default), a value of more like 50 PGs per OSD is probably reasonable. The challenge (which the autoscaler normally does for you), is to:
have the PGs per pool proportional to the data in the pool, and
end up with 50-100 PGs per OSDs, after the replication or erasuring-coding fan-out of each PG across OSDs is taken into consideration
How are Placement Groups used ?¶
A placement group (PG) aggregates objects within a pool because tracking object placement and object metadata on a per-object basis is computationally expensive–i.e., a system with millions of objects cannot realistically track placement on a per-object basis.
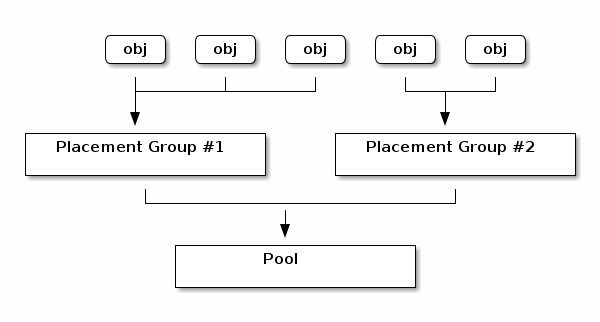
The Ceph client will calculate which placement group an object should be in. It does this by hashing the object ID and applying an operation based on the number of PGs in the defined pool and the ID of the pool. See Mapping PGs to OSDs for details.
The object’s contents within a placement group are stored in a set of OSDs. For instance, in a replicated pool of size two, each placement group will store objects on two OSDs, as shown below.
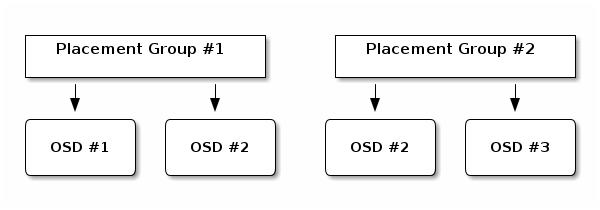
Should OSD #2 fail, another will be assigned to Placement Group #1 and will be filled with copies of all objects in OSD #1. If the pool size is changed from two to three, an additional OSD will be assigned to the placement group and will receive copies of all objects in the placement group.
Placement groups do not own the OSD; they share it with other placement groups from the same pool or even other pools. If OSD #2 fails, the Placement Group #2 will also have to restore copies of objects, using OSD #3.
When the number of placement groups increases, the new placement groups will be assigned OSDs. The result of the CRUSH function will also change and some objects from the former placement groups will be copied over to the new Placement Groups and removed from the old ones.
Placement Groups Tradeoffs¶
Data durability and even distribution among all OSDs call for more placement groups but their number should be reduced to the minimum to save CPU and memory.
Data durability¶
After an OSD fails, the risk of data loss increases until the data it contained is fully recovered. Let’s imagine a scenario that causes permanent data loss in a single placement group:
The OSD fails and all copies of the object it contains are lost. For all objects within the placement group the number of replica suddenly drops from three to two.
Ceph starts recovery for this placement group by choosing a new OSD to re-create the third copy of all objects.
Another OSD, within the same placement group, fails before the new OSD is fully populated with the third copy. Some objects will then only have one surviving copies.
Ceph picks yet another OSD and keeps copying objects to restore the desired number of copies.
A third OSD, within the same placement group, fails before recovery is complete. If this OSD contained the only remaining copy of an object, it is permanently lost.
In a cluster containing 10 OSDs with 512 placement groups in a three replica pool, CRUSH will give each placement groups three OSDs. In the end, each OSDs will end up hosting (512 * 3) / 10 = ~150 Placement Groups. When the first OSD fails, the above scenario will therefore start recovery for all 150 placement groups at the same time.
The 150 placement groups being recovered are likely to be homogeneously spread over the 9 remaining OSDs. Each remaining OSD is therefore likely to send copies of objects to all others and also receive some new objects to be stored because they became part of a new placement group.
The amount of time it takes for this recovery to complete entirely depends on the architecture of the Ceph cluster. Let say each OSD is hosted by a 1TB SSD on a single machine and all of them are connected to a 10Gb/s switch and the recovery for a single OSD completes within M minutes. If there are two OSDs per machine using spinners with no SSD journal and a 1Gb/s switch, it will at least be an order of magnitude slower.
In a cluster of this size, the number of placement groups has almost no influence on data durability. It could be 128 or 8192 and the recovery would not be slower or faster.
However, growing the same Ceph cluster to 20 OSDs instead of 10 OSDs is likely to speed up recovery and therefore improve data durability significantly. Each OSD now participates in only ~75 placement groups instead of ~150 when there were only 10 OSDs and it will still require all 19 remaining OSDs to perform the same amount of object copies in order to recover. But where 10 OSDs had to copy approximately 100GB each, they now have to copy 50GB each instead. If the network was the bottleneck, recovery will happen twice as fast. In other words, recovery goes faster when the number of OSDs increases.
If this cluster grows to 40 OSDs, each of them will only host ~35 placement groups. If an OSD dies, recovery will keep going faster unless it is blocked by another bottleneck. However, if this cluster grows to 200 OSDs, each of them will only host ~7 placement groups. If an OSD dies, recovery will happen between at most of ~21 (7 * 3) OSDs in these placement groups: recovery will take longer than when there were 40 OSDs, meaning the number of placement groups should be increased.
No matter how short the recovery time is, there is a chance for a second OSD to fail while it is in progress. In the 10 OSDs cluster described above, if any of them fail, then ~17 placement groups (i.e. ~150 / 9 placement groups being recovered) will only have one surviving copy. And if any of the 8 remaining OSD fail, the last objects of two placement groups are likely to be lost (i.e. ~17 / 8 placement groups with only one remaining copy being recovered).
When the size of the cluster grows to 20 OSDs, the number of Placement Groups damaged by the loss of three OSDs drops. The second OSD lost will degrade ~4 (i.e. ~75 / 19 placement groups being recovered) instead of ~17 and the third OSD lost will only lose data if it is one of the four OSDs containing the surviving copy. In other words, if the probability of losing one OSD is 0.0001% during the recovery time frame, it goes from 17 * 10 * 0.0001% in the cluster with 10 OSDs to 4 * 20 * 0.0001% in the cluster with 20 OSDs.
In a nutshell, more OSDs mean faster recovery and a lower risk of cascading failures leading to the permanent loss of a Placement Group. Having 512 or 4096 Placement Groups is roughly equivalent in a cluster with less than 50 OSDs as far as data durability is concerned.
Note: It may take a long time for a new OSD added to the cluster to be populated with placement groups that were assigned to it. However there is no degradation of any object and it has no impact on the durability of the data contained in the Cluster.
Object distribution within a pool¶
Ideally objects are evenly distributed in each placement group. Since CRUSH computes the placement group for each object, but does not actually know how much data is stored in each OSD within this placement group, the ratio between the number of placement groups and the number of OSDs may influence the distribution of the data significantly.
For instance, if there was a single placement group for ten OSDs in a three replica pool, only three OSD would be used because CRUSH would have no other choice. When more placement groups are available, objects are more likely to be evenly spread among them. CRUSH also makes every effort to evenly spread OSDs among all existing Placement Groups.
As long as there are one or two orders of magnitude more Placement Groups than OSDs, the distribution should be even. For instance, 256 placement groups for 3 OSDs, 512 or 1024 placement groups for 10 OSDs etc.
Uneven data distribution can be caused by factors other than the ratio between OSDs and placement groups. Since CRUSH does not take into account the size of the objects, a few very large objects may create an imbalance. Let say one million 4K objects totaling 4GB are evenly spread among 1024 placement groups on 10 OSDs. They will use 4GB / 10 = 400MB on each OSD. If one 400MB object is added to the pool, the three OSDs supporting the placement group in which the object has been placed will be filled with 400MB + 400MB = 800MB while the seven others will remain occupied with only 400MB.
Memory, CPU and network usage¶
For each placement group, OSDs and MONs need memory, network and CPU at all times and even more during recovery. Sharing this overhead by clustering objects within a placement group is one of the main reasons they exist.
Minimizing the number of placement groups saves significant amounts of resources.
Choosing the number of Placement Groups¶
If you have more than 50 OSDs, we recommend approximately 50-100 placement groups per OSD to balance out resource usage, data durability and distribution. If you have less than 50 OSDs, choosing among the preselection above is best. For a single pool of objects, you can use the following formula to get a baseline
Total PGs = \(\frac{OSDs \times 100}{pool \: size}\)
Where pool size is either the number of replicas for replicated pools or the K+M sum for erasure coded pools (as returned by ceph osd erasure-code-profile get).
You should then check if the result makes sense with the way you designed your Ceph cluster to maximize data durability, object distribution and minimize resource usage.
The result should always be rounded up to the nearest power of two.
Only a power of two will evenly balance the number of objects among placement groups. Other values will result in an uneven distribution of data across your OSDs. Their use should be limited to incrementally stepping from one power of two to another.
As an example, for a cluster with 200 OSDs and a pool size of 3 replicas, you would estimate your number of PGs as follows
\(\frac{200 \times 100}{3} = 6667\). Nearest power of 2: 8192
When using multiple data pools for storing objects, you need to ensure that you balance the number of placement groups per pool with the number of placement groups per OSD so that you arrive at a reasonable total number of placement groups that provides reasonably low variance per OSD without taxing system resources or making the peering process too slow.
For instance a cluster of 10 pools each with 512 placement groups on ten OSDs is a total of 5,120 placement groups spread over ten OSDs, that is 512 placement groups per OSD. That does not use too many resources. However, if 1,000 pools were created with 512 placement groups each, the OSDs will handle ~50,000 placement groups each and it would require significantly more resources and time for peering.
You may find the PGCalc tool helpful.
Set the Number of Placement Groups¶
To set the number of placement groups in a pool, you must specify the number of placement groups at the time you create the pool. See Create a Pool for details. Even after a pool is created you can also change the number of placement groups with:
ceph osd pool set {pool-name} pg_num {pg_num}
After you increase the number of placement groups, you must also
increase the number of placement groups for placement (pgp_num)
before your cluster will rebalance. The pgp_num will be the number of
placement groups that will be considered for placement by the CRUSH
algorithm. Increasing pg_num splits the placement groups but data
will not be migrated to the newer placement groups until placement
groups for placement, ie. pgp_num is increased. The pgp_num
should be equal to the pg_num. To increase the number of
placement groups for placement, execute the following:
ceph osd pool set {pool-name} pgp_num {pgp_num}
When decreasing the number of PGs, pgp_num is adjusted
automatically for you.
Get the Number of Placement Groups¶
To get the number of placement groups in a pool, execute the following:
ceph osd pool get {pool-name} pg_num
Get a Cluster’s PG Statistics¶
To get the statistics for the placement groups in your cluster, execute the following:
ceph pg dump [--format {format}]
Valid formats are plain (default) and json.
Get Statistics for Stuck PGs¶
To get the statistics for all placement groups stuck in a specified state, execute the following:
ceph pg dump_stuck inactive|unclean|stale|undersized|degraded [--format <format>] [-t|--threshold <seconds>]
Inactive Placement groups cannot process reads or writes because they are waiting for an OSD with the most up-to-date data to come up and in.
Unclean Placement groups contain objects that are not replicated the desired number of times. They should be recovering.
Stale Placement groups are in an unknown state - the OSDs that host them have not
reported to the monitor cluster in a while (configured by mon_osd_report_timeout).
Valid formats are plain (default) and json. The threshold defines the minimum number
of seconds the placement group is stuck before including it in the returned statistics
(default 300 seconds).
Get a PG Map¶
To get the placement group map for a particular placement group, execute the following:
ceph pg map {pg-id}
For example:
ceph pg map 1.6c
Ceph will return the placement group map, the placement group, and the OSD status:
osdmap e13 pg 1.6c (1.6c) -> up [1,0] acting [1,0]
Get a PGs Statistics¶
To retrieve statistics for a particular placement group, execute the following:
ceph pg {pg-id} query
Scrub a Placement Group¶
To scrub a placement group, execute the following:
ceph pg scrub {pg-id}
Ceph checks the primary and any replica nodes, generates a catalog of all objects in the placement group and compares them to ensure that no objects are missing or mismatched, and their contents are consistent. Assuming the replicas all match, a final semantic sweep ensures that all of the snapshot-related object metadata is consistent. Errors are reported via logs.
To scrub all placement groups from a specific pool, execute the following:
ceph osd pool scrub {pool-name}
Prioritize backfill/recovery of a Placement Group(s)¶
You may run into a situation where a bunch of placement groups will require recovery and/or backfill, and some particular groups hold data more important than others (for example, those PGs may hold data for images used by running machines and other PGs may be used by inactive machines/less relevant data). In that case, you may want to prioritize recovery of those groups so performance and/or availability of data stored on those groups is restored earlier. To do this (mark particular placement group(s) as prioritized during backfill or recovery), execute the following:
ceph pg force-recovery {pg-id} [{pg-id #2}] [{pg-id #3} ...]
ceph pg force-backfill {pg-id} [{pg-id #2}] [{pg-id #3} ...]
This will cause Ceph to perform recovery or backfill on specified placement groups first, before other placement groups. This does not interrupt currently ongoing backfills or recovery, but causes specified PGs to be processed as soon as possible. If you change your mind or prioritize wrong groups, use:
ceph pg cancel-force-recovery {pg-id} [{pg-id #2}] [{pg-id #3} ...]
ceph pg cancel-force-backfill {pg-id} [{pg-id #2}] [{pg-id #3} ...]
This will remove “force” flag from those PGs and they will be processed in default order. Again, this doesn’t affect currently processed placement group, only those that are still queued.
The “force” flag is cleared automatically after recovery or backfill of group is done.
Similarly, you may use the following commands to force Ceph to perform recovery or backfill on all placement groups from a specified pool first:
ceph osd pool force-recovery {pool-name}
ceph osd pool force-backfill {pool-name}
or:
ceph osd pool cancel-force-recovery {pool-name}
ceph osd pool cancel-force-backfill {pool-name}
to restore to the default recovery or backfill priority if you change your mind.
Note that these commands could possibly break the ordering of Ceph’s internal priority computations, so use them with caution! Especially, if you have multiple pools that are currently sharing the same underlying OSDs, and some particular pools hold data more important than others, we recommend you use the following command to re-arrange all pools’s recovery/backfill priority in a better order:
ceph osd pool set {pool-name} recovery_priority {value}
For example, if you have 10 pools you could make the most important one priority 10, next 9, etc. Or you could leave most pools alone and have say 3 important pools all priority 1 or priorities 3, 2, 1 respectively.
Revert Lost¶
If the cluster has lost one or more objects, and you have decided to
abandon the search for the lost data, you must mark the unfound objects
as lost.
If all possible locations have been queried and objects are still lost, you may have to give up on the lost objects. This is possible given unusual combinations of failures that allow the cluster to learn about writes that were performed before the writes themselves are recovered.
Currently the only supported option is “revert”, which will either roll back to a previous version of the object or (if it was a new object) forget about it entirely. To mark the “unfound” objects as “lost”, execute the following:
ceph pg {pg-id} mark_unfound_lost revert|delete
Important
Use this feature with caution, because it may confuse applications that expect the object(s) to exist.