Cache Tiering
Warning
Cache tiering has been deprecated in the Reef release as it has lacked a maintainer for a very long time. This does not mean it will be certainly removed, but we may choose to remove it without much further notice.
A cache tier provides Ceph Clients with better I/O performance for a subset of the data stored in a backing storage tier. Cache tiering involves creating a pool of relatively fast/expensive storage devices (e.g., solid state drives) configured to act as a cache tier, and a backing pool of either erasure-coded or relatively slower/cheaper devices configured to act as an economical storage tier. The Ceph objecter handles where to place the objects and the tiering agent determines when to flush objects from the cache to the backing storage tier. So the cache tier and the backing storage tier are completely transparent to Ceph clients.
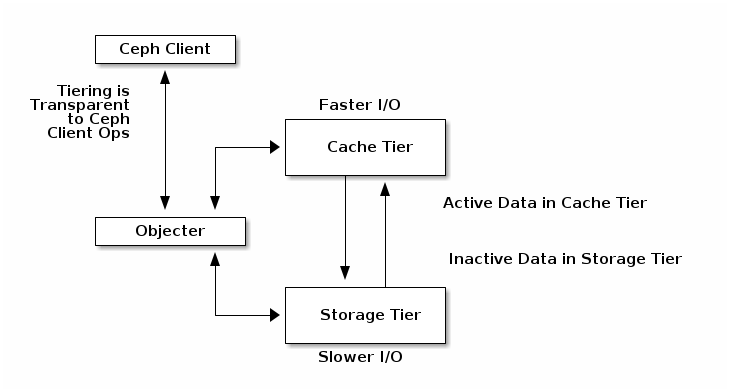
The cache tiering agent handles the migration of data between the cache tier
and the backing storage tier automatically. However, admins have the ability to
configure how this migration takes place by setting the cache-mode. There are
two main scenarios:
writeback mode: If the base tier and the cache tier are configured in
writebackmode, Ceph clients receive an ACK from the base tier every time they write data to it. Then the cache tiering agent determines whetherosd_tier_default_cache_min_write_recency_for_promotehas been set. If it has been set and the data has been written more than a specified number of times per interval, the data is promoted to the cache tier.When Ceph clients need access to data stored in the base tier, the cache tiering agent reads the data from the base tier and returns it to the client. While data is being read from the base tier, the cache tiering agent consults the value of
osd_tier_default_cache_min_read_recency_for_promoteand decides whether to promote that data from the base tier to the cache tier. When data has been promoted from the base tier to the cache tier, the Ceph client is able to perform I/O operations on it using the cache tier. This is well-suited for mutable data (for example, photo/video editing, transactional data).readproxy mode: This mode will use any objects that already exist in the cache tier, but if an object is not present in the cache the request will be proxied to the base tier. This is useful for transitioning from
writebackmode to a disabled cache as it allows the workload to function properly while the cache is drained, without adding any new objects to the cache.
Other cache modes are:
readonly promotes objects to the cache on read operations only; write operations are forwarded to the base tier. This mode is intended for read-only workloads that do not require consistency to be enforced by the storage system. (Warning: when objects are updated in the base tier, Ceph makes no attempt to sync these updates to the corresponding objects in the cache. Since this mode is considered experimental, a
--yes-i-really-mean-itoption must be passed in order to enable it.)none is used to completely disable caching.
A word of caution
Cache tiering will degrade performance for most workloads. Users should use extreme caution before using this feature.
Workload dependent: Whether a cache will improve performance is highly dependent on the workload. Because there is a cost associated with moving objects into or out of the cache, it can only be effective when there is a large skew in the access pattern in the data set, such that most of the requests touch a small number of objects. The cache pool should be large enough to capture the working set for your workload to avoid thrashing.
Difficult to benchmark: Most benchmarks that users run to measure performance will show terrible performance with cache tiering, in part because very few of them skew requests toward a small set of objects, it can take a long time for the cache to “warm up,” and because the warm-up cost can be high.
Usually slower: For workloads that are not cache tiering-friendly, performance is often slower than a normal RADOS pool without cache tiering enabled.
librados object enumeration: The librados-level object enumeration API is not meant to be coherent in the presence of the case. If your application is using librados directly and relies on object enumeration, cache tiering will probably not work as expected. (This is not a problem for RGW, RBD, or CephFS.)
Complexity: Enabling cache tiering means that a lot of additional machinery and complexity within the RADOS cluster is being used. This increases the probability that you will encounter a bug in the system that other users have not yet encountered and will put your deployment at a higher level of risk.
Known Good Workloads
RGW time-skewed: If the RGW workload is such that almost all read operations are directed at recently written objects, a simple cache tiering configuration that destages recently written objects from the cache to the base tier after a configurable period can work well.
Known Bad Workloads
The following configurations are known to work poorly with cache tiering.
RBD with replicated cache and erasure-coded base: This is a common request, but usually does not perform well. Even reasonably skewed workloads still send some small writes to cold objects, and because small writes are not yet supported by the erasure-coded pool, entire (usually 4 MB) objects must be migrated into the cache in order to satisfy a small (often 4 KB) write. Only a handful of users have successfully deployed this configuration, and it only works for them because their data is extremely cold (backups) and they are not in any way sensitive to performance.
RBD with replicated cache and base: RBD with a replicated base tier does better than when the base is erasure coded, but it is still highly dependent on the amount of skew in the workload, and very difficult to validate. The user will need to have a good understanding of their workload and will need to tune the cache tiering parameters carefully.
Setting Up Pools
To set up cache tiering, you must have two pools. One will act as the backing storage and the other will act as the cache.
Setting Up a Backing Storage Pool
Setting up a backing storage pool typically involves one of two scenarios:
Standard Storage: In this scenario, the pool stores multiple copies of an object in the Ceph Storage Cluster.
Erasure Coding: In this scenario, the pool uses erasure coding to store data much more efficiently with a small performance tradeoff.
In the standard storage scenario, you can setup a CRUSH rule to establish the failure domain (e.g., osd, host, chassis, rack, row, etc.). Ceph OSD Daemons perform optimally when all storage drives in the rule are of the same size, speed (both RPMs and throughput) and type. See CRUSH Maps for details on creating a rule. Once you have created a rule, create a backing storage pool.
In the erasure coding scenario, the pool creation arguments will generate the appropriate rule automatically. See Create a Pool for details.
In subsequent examples, we will refer to the backing storage pool
as cold-storage.
Setting Up a Cache Pool
Setting up a cache pool follows the same procedure as the standard storage scenario, but with this difference: the drives for the cache tier are typically high performance drives that reside in their own servers and have their own CRUSH rule. When setting up such a rule, it should take account of the hosts that have the high performance drives while omitting the hosts that don’t. See CRUSH Device Class for details.
In subsequent examples, we will refer to the cache pool as hot-storage and
the backing pool as cold-storage.
For cache tier configuration and default values, see Pools - Set Pool Values.
Creating a Cache Tier
Setting up a cache tier involves associating a backing storage pool with a cache pool:
ceph osd tier add {storagepool} {cachepool}
For example:
ceph osd tier add cold-storage hot-storage
To set the cache mode, execute the following:
ceph osd tier cache-mode {cachepool} {cache-mode}
For example:
ceph osd tier cache-mode hot-storage writeback
The cache tiers overlay the backing storage tier, so they require one additional step: you must direct all client traffic from the storage pool to the cache pool. To direct client traffic directly to the cache pool, execute the following:
ceph osd tier set-overlay {storagepool} {cachepool}
For example:
ceph osd tier set-overlay cold-storage hot-storage
Configuring a Cache Tier
Cache tiers have several configuration options. You may set cache tier configuration options with the following usage:
ceph osd pool set {cachepool} {key} {value}
See Pools - Set Pool Values for details.
Target Size and Type
Ceph’s production cache tiers use a Bloom Filter for the hit_set_type:
ceph osd pool set {cachepool} hit_set_type bloom
For example:
ceph osd pool set hot-storage hit_set_type bloom
The hit_set_count and hit_set_period define how many such HitSets to
store, and how much time each HitSet should cover:
ceph osd pool set {cachepool} hit_set_count 12
ceph osd pool set {cachepool} hit_set_period 14400
ceph osd pool set {cachepool} target_max_bytes 1000000000000
Note
A larger hit_set_count results in more RAM consumed by
the ceph-osd process.
Binning accesses over time allows Ceph to determine whether a Ceph client accessed an object at least once, or more than once over a time period (“age” vs “temperature”).
The min_read_recency_for_promote defines how many HitSets to check for the
existence of an object when handling a read operation. The checking result is
used to decide whether to promote the object asynchronously. Its value should be
between 0 and hit_set_count. If it’s set to 0, the object is always promoted.
If it’s set to 1, the current HitSet is checked. And if this object is in the
current HitSet, it’s promoted. Otherwise not. For the other values, the exact
number of archive HitSets are checked. The object is promoted if the object is
found in any of the most recent min_read_recency_for_promote HitSets.
A similar parameter can be set for the write operation, which is
min_write_recency_for_promote:
ceph osd pool set {cachepool} min_read_recency_for_promote 2
ceph osd pool set {cachepool} min_write_recency_for_promote 2
Note
The longer the period and the higher the
min_read_recency_for_promote and
min_write_recency_for_promote``values, the more RAM the ``ceph-osd
daemon consumes. In particular, when the agent is active to flush
or evict cache objects, all hit_set_count HitSets are loaded
into RAM.
Cache Sizing
The cache tiering agent performs two main functions:
Flushing: The agent identifies modified (or dirty) objects and forwards them to the storage pool for long-term storage.
Evicting: The agent identifies objects that haven’t been modified (or clean) and evicts the least recently used among them from the cache.
Absolute Sizing
The cache tiering agent can flush or evict objects based upon the total number of bytes or the total number of objects. To specify a maximum number of bytes, execute the following:
ceph osd pool set {cachepool} target_max_bytes {#bytes}
For example, to flush or evict at 1 TB, execute the following:
ceph osd pool set hot-storage target_max_bytes 1099511627776
To specify the maximum number of objects, execute the following:
ceph osd pool set {cachepool} target_max_objects {#objects}
For example, to flush or evict at 1M objects, execute the following:
ceph osd pool set hot-storage target_max_objects 1000000
Note
Ceph is not able to determine the size of a cache pool automatically, so the configuration on the absolute size is required here, otherwise the flush/evict will not work. If you specify both limits, the cache tiering agent will begin flushing or evicting when either threshold is triggered.
Note
All client requests will be blocked only when target_max_bytes or
target_max_objects reached
Relative Sizing
The cache tiering agent can flush or evict objects relative to the size of the
cache pool(specified by target_max_bytes / target_max_objects in
Absolute sizing). When the cache pool consists of a certain percentage of
modified (or dirty) objects, the cache tiering agent will flush them to the
storage pool. To set the cache_target_dirty_ratio, execute the following:
ceph osd pool set {cachepool} cache_target_dirty_ratio {0.0..1.0}
For example, setting the value to 0.4 will begin flushing modified
(dirty) objects when they reach 40% of the cache pool’s capacity:
ceph osd pool set hot-storage cache_target_dirty_ratio 0.4
When the dirty objects reaches a certain percentage of its capacity, flush dirty
objects with a higher speed. To set the cache_target_dirty_high_ratio:
ceph osd pool set {cachepool} cache_target_dirty_high_ratio {0.0..1.0}
For example, setting the value to 0.6 will begin aggressively flush dirty
objects when they reach 60% of the cache pool’s capacity. obviously, we’d
better set the value between dirty_ratio and full_ratio:
ceph osd pool set hot-storage cache_target_dirty_high_ratio 0.6
When the cache pool reaches a certain percentage of its capacity, the cache
tiering agent will evict objects to maintain free capacity. To set the
cache_target_full_ratio, execute the following:
ceph osd pool set {cachepool} cache_target_full_ratio {0.0..1.0}
For example, setting the value to 0.8 will begin flushing unmodified
(clean) objects when they reach 80% of the cache pool’s capacity:
ceph osd pool set hot-storage cache_target_full_ratio 0.8
Cache Age
You can specify the minimum age of an object before the cache tiering agent flushes a recently modified (or dirty) object to the backing storage pool:
ceph osd pool set {cachepool} cache_min_flush_age {#seconds}
For example, to flush modified (or dirty) objects after 10 minutes, execute the following:
ceph osd pool set hot-storage cache_min_flush_age 600
You can specify the minimum age of an object before it will be evicted from the cache tier:
ceph osd pool {cache-tier} cache_min_evict_age {#seconds}
For example, to evict objects after 30 minutes, execute the following:
ceph osd pool set hot-storage cache_min_evict_age 1800
Removing a Cache Tier
Removing a cache tier differs depending on whether it is a writeback cache or a read-only cache.
Removing a Read-Only Cache
Since a read-only cache does not have modified data, you can disable and remove it without losing any recent changes to objects in the cache.
Change the cache-mode to
noneto disable it.:ceph osd tier cache-mode {cachepool} noneFor example:
ceph osd tier cache-mode hot-storage noneRemove the cache pool from the backing pool.:
ceph osd tier remove {storagepool} {cachepool}For example:
ceph osd tier remove cold-storage hot-storage
Removing a Writeback Cache
Since a writeback cache may have modified data, you must take steps to ensure that you do not lose any recent changes to objects in the cache before you disable and remove it.
Change the cache mode to
proxyso that new and modified objects will flush to the backing storage pool.:ceph osd tier cache-mode {cachepool} proxyFor example:
ceph osd tier cache-mode hot-storage proxyEnsure that the cache pool has been flushed. This may take a few minutes:
rados -p {cachepool} lsIf the cache pool still has objects, you can flush them manually. For example:
rados -p {cachepool} cache-flush-evict-allRemove the overlay so that clients will not direct traffic to the cache.:
ceph osd tier remove-overlay {storagetier}For example:
ceph osd tier remove-overlay cold-storageFinally, remove the cache tier pool from the backing storage pool.:
ceph osd tier remove {storagepool} {cachepool}For example:
ceph osd tier remove cold-storage hot-storage
Troubleshooting Unfound Objects
Under certain circumstances, restarting OSDs may result in unfound objects.
Here is an example of unfound objects appearing during an upgrade from Ceph 14.2.6 to Ceph 14.2.7:
2/543658058 objects unfound (0.000%)
pg 19.12 has 1 unfound objects
pg 19.2d has 1 unfound objects
Possible data damage: 2 pgs recovery_unfound
pg 19.12 is active+recovery_unfound+undersized+degraded+remapped, acting [299,310], 1 unfound
pg 19.2d is active+recovery_unfound+undersized+degraded+remapped, acting [290,309], 1 unfound
# ceph pg 19.12 list_unfound
{
"num_missing": 1,
"num_unfound": 1,
"objects": [
{
"oid": {
"oid": "hit_set_19.12_archive_2020-02-25 13:43:50.256316Z_2020-02-25 13:43:50.325825Z",
"key": "",
"snapid": -2,
"hash": 18,
"max": 0,
"pool": 19,
"namespace": ".ceph-internal"
},
"need": "3312398'55868341",
"have": "0'0",
"flags": "none",
"locations": []
}
],
"more": false
Some tests in the field indicate that the unfound objects can be deleted with
no adverse effects (see Tracker Issue #44286, Note 3). Pawel Stefanski suggests
that deleting missing or unfound objects is safe as long as the objects are a
part of .ceph-internal::hit_set_PGID_archive.
Various members of the upstream Ceph community have reported in Tracker Issue #44286 that the following versions of Ceph have been affected by this issue:
14.2.8
14.2.16
15.2.15
16.2.5
17.2.7
See Tracker Issue #44286 for the history of this issue.